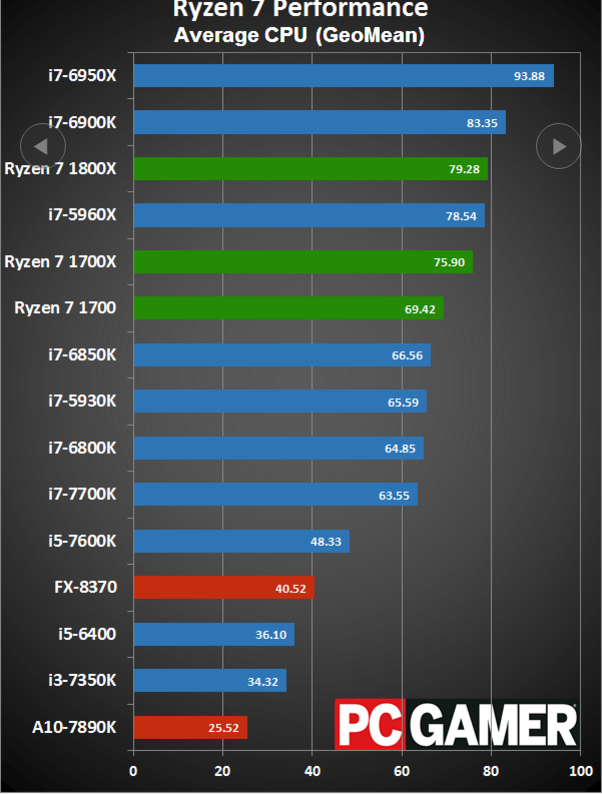
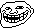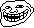Вот и настал конец десятилетней тик-так стратегии Intel. Свежие официальные данные: Ryzen 1800X производительнее на 9 процентов в многопоточке(Cinebench R15) топового Core i7-6900K на Broadwell-E и при этом в два раза дешевле. Будет доступен для предзаказа со 2 марта.
Ждём официальную дату запуска в продажу Middle-End процессоров.
______________
Windows 10 - 1080 Ultra DX11:
8C/16T - 49.39fps (Min), 72.36fps (Avg)
8C/8T - 57.16fps (Min), 72.46fps (Avg)Windows 7 - 1080 Ultra DX11:
8C/16T - 62.33fps (Min), 78.18fps (Avg)
8C/8T - 62.00fps (Min), 73.22fps (Avg)
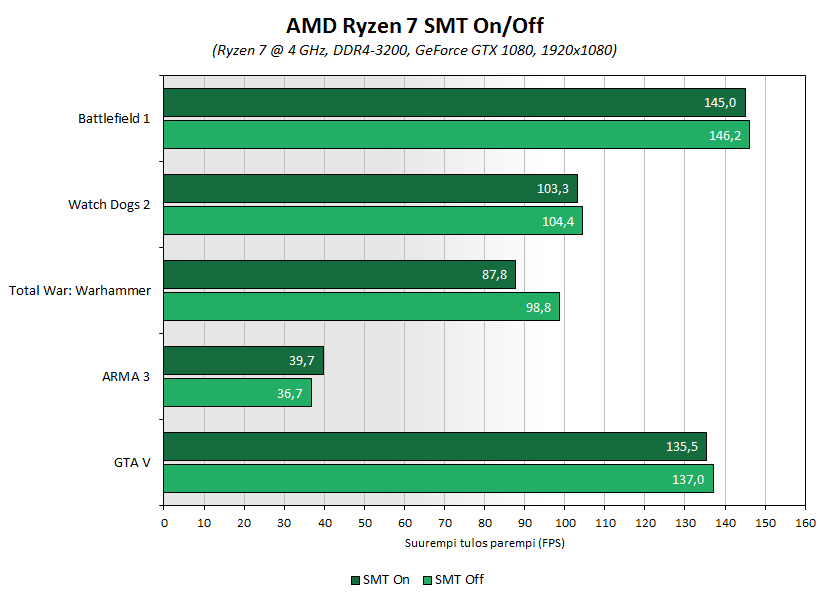
Влияние SMTна FPS. После некоторых тестов с отключенным SMT многие сделали неверные выводы о том, что SMT снижает FPS в играх. Это не так. Дело в том, что в 16 поточном режиме ядра у Ryzen недогружены, по-этому он работает в играх на своих базовых 3.6ГГц, которых явно не хватит для топовых вершин FPS. При отключении SMT нагрузка на оставшиеся 8 потоков возрастает и начинает работать Prescion Boost. Возрастает частота процессора, возрастают и FPS. Потому и возникают такие ситуации, что Ryzen R7 1700 на 3.9 ГГц быстрее, чем стоковый 1800X. Там где игры способны загружать много потоков отключение SMT не даст какой-либо ощутимой прибавки, потому что Буст ядер и так работает. Но в играх с малопоточной оптимизацией отключение SMT позволит лучше нагрузить оставшиеся ядра.
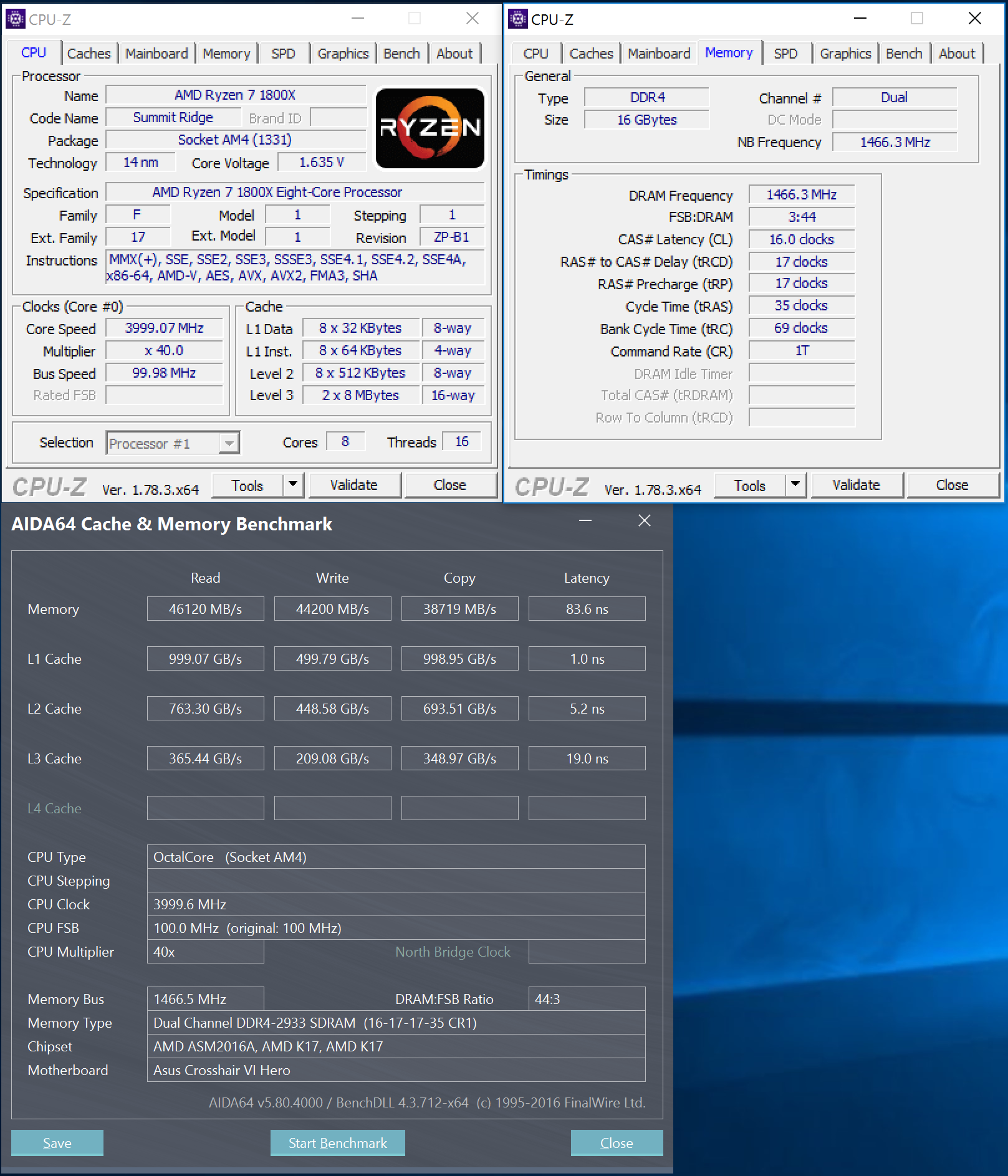
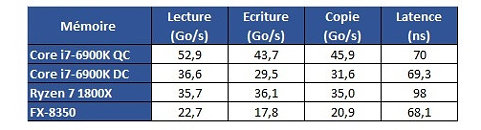
Оперативная память. Так уж вышло, что в новой архитектуре Zen контроллер памяти работает на частоте оперативной памяти. Абсолютно большинство тестировщиков использовали для обзоров первой волны модули памяти с частотой 2133/2400. Для Ryzen это очень мало. Нужно использовать модули с частотой 3200 МГц и выше. Эти 3200 МГц способны очень сильно поднять FPS.

Повышенная латентность памяти. Да, есть. Латентность памяти никак не влияет на производительность в играх. Если вспомнить, то в PS4 используется GDDR5 как графическая и системная память. Латентность GDDR5 куда выше DDR4 памяти, и никаких особых трудностей в играх это не вызывает. Так что обзорщики, из-за своей некомпетентности, особенно Ильюша с 3DNews, пришли к не верным выводам. Да и не сказать, что у Ryzen катастрофическая латентность памяти. У тех же Carrizo/Bristol Ridge она гораздо выше.
Поддержка планок памяти с высокой частотой. На ранних этапах подготовки к обзорам выяснилось, что у некоторых производителей материнских плат, особенно у ASUS, очень корявые БИОСы и не могут в высокочастотную память. Уже пофикшено.
Нюансы c памятью. Ryzen поддерживает память с ECC. Многие производители уже выпустили комплекты памяти 3200МГц специально для работы с Ryzen. Выбирайте лучшее ее, чем модули по 2133/2400.

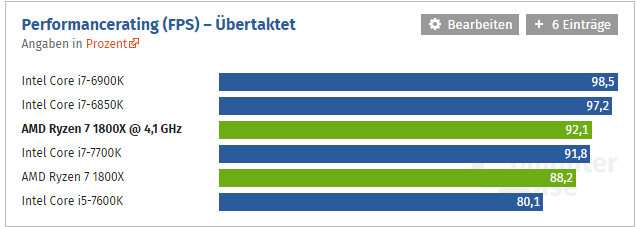
И это с кривым Скедуллером и неизвестной памятью! Не плохо за свои деньги!